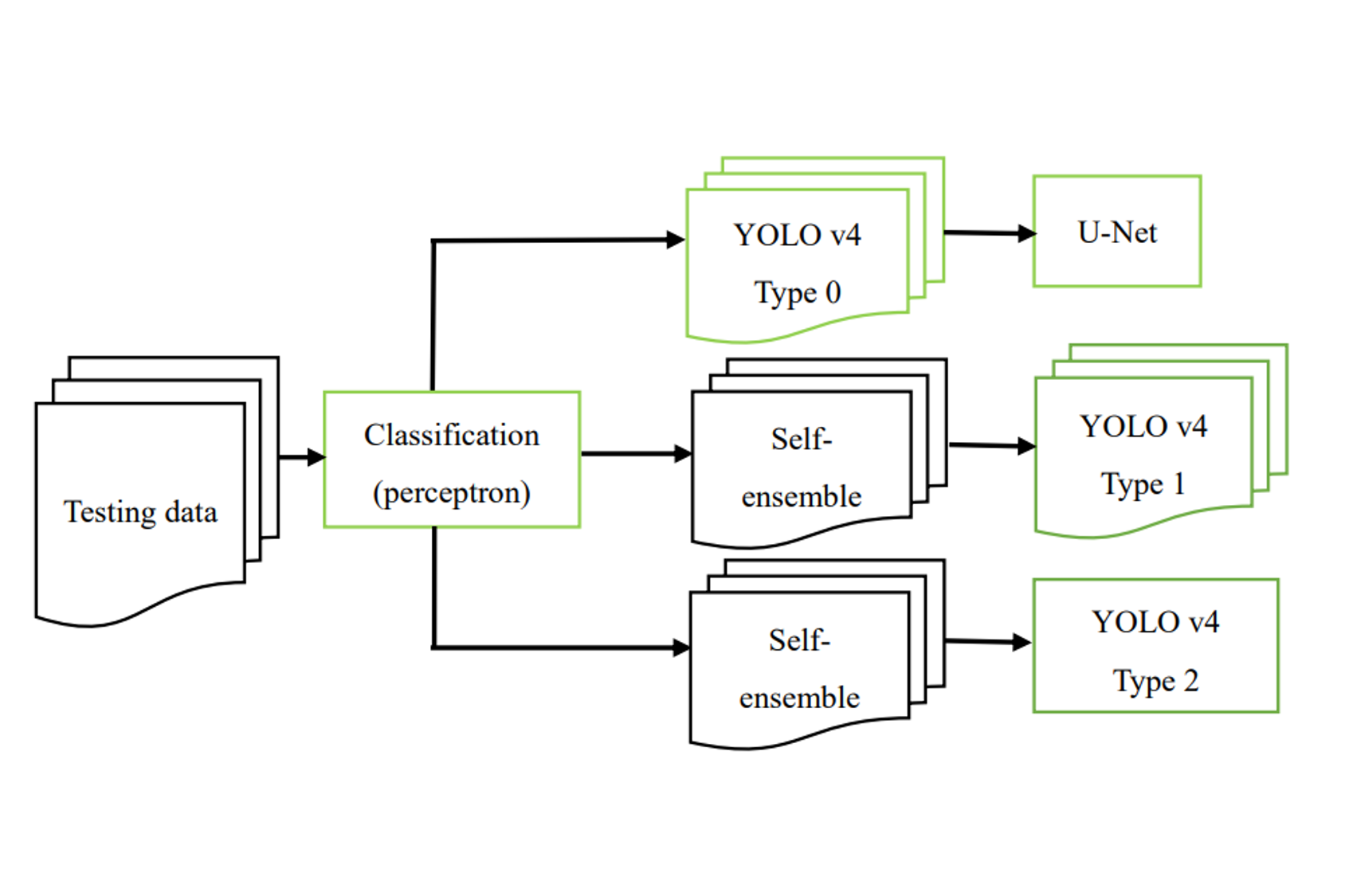
AI R&D 工程師 2022 - now
於華碩的 DIT部門擔任 AI研發工程師,除了需要對於電腦視覺的AI演算法有一定程度理解之外,也須結合前端或後端的程式能力以建構解決方案的應用程式。
大家好!我叫范植貿,你也可以叫我阿貿。 畢業於國立中興大學電機系碩士學位,主修計算機科學、電腦視覺 與 人工智慧。
目前於台灣台北華碩 的 數位影像技術部 擔任 AI研發工程師。 我對任何新鮮有趣的事物都非常有興趣,並熱衷學習,渴望參與接觸沒學過的新技術。
如果你想知道關於我的更多經歷與著作,可以參考下面資訊~!
碩士畢業於國立中興大學電機工程學系,主修電腦視覺與人工智慧,研究領域為影像修復任務。 期間取得傑出的在校成績 GPA: 4.13/4.15,且參與多個深度學習程式競賽,包括: 資料分析、物件偵測與影像分割等。 並且發表 4 篇論文並被接受與發表至 ICIP、EUSIPCO 與 ISCAS 等國際會議,且碩士論文被選為 2022 IEEE 台北分會最佳碩博士論文獎。 期望能不斷精進自己程式能力以解決現實生活中所遇到的問題。
大學畢業於元智大學電機工程學系,主修電子、電路與電磁學,也包含基礎的程式課程包括: 資料結構、C語言等。 畢業專題針對 Android 手機應用程式開發,利用了 JavaScript,SQL 與 socket連線等技術,也藉有此專題發現自己相較於偏向硬體的技術,更喜歡軟體的開發。
於華碩的 DIT部門擔任 AI研發工程師,除了需要對於電腦視覺的AI演算法有一定程度理解之外,也須結合前端或後端的程式能力以建構解決方案的應用程式。
複合多分支特徵融合用於真實圖像修復
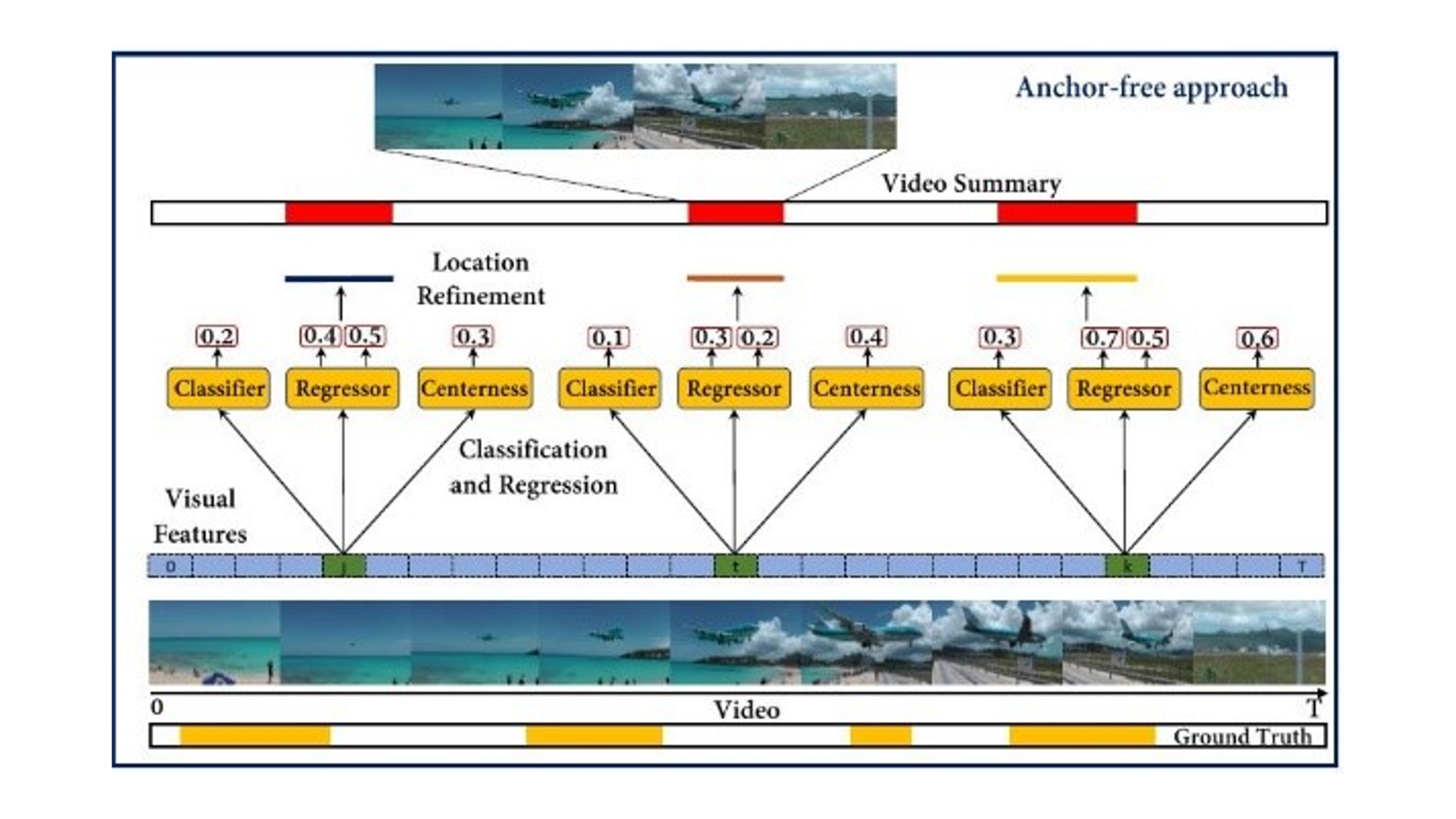
圖像修復是一個具有挑戰性且為一種 ill-posed 問題,這也是一個長期存在的問題。然而,大多數基於學習的修復方法僅針對一種類型的退化,這意味著它們缺乏泛化能力。在本文中,我們提出了一種受到人類視覺系統(即視網膜神經節細胞)啟發的多分支修復模型,該模型可以在一個通用框架中實現多種修復任務。實驗結果顯示,所提出的多分支架構,稱為CMFNet,在四個數據集上的表現具有競爭力,這些數據集包括圖像去模糊、去霧和去雨滴,這些應用在自動駕駛汽車中非常常見。

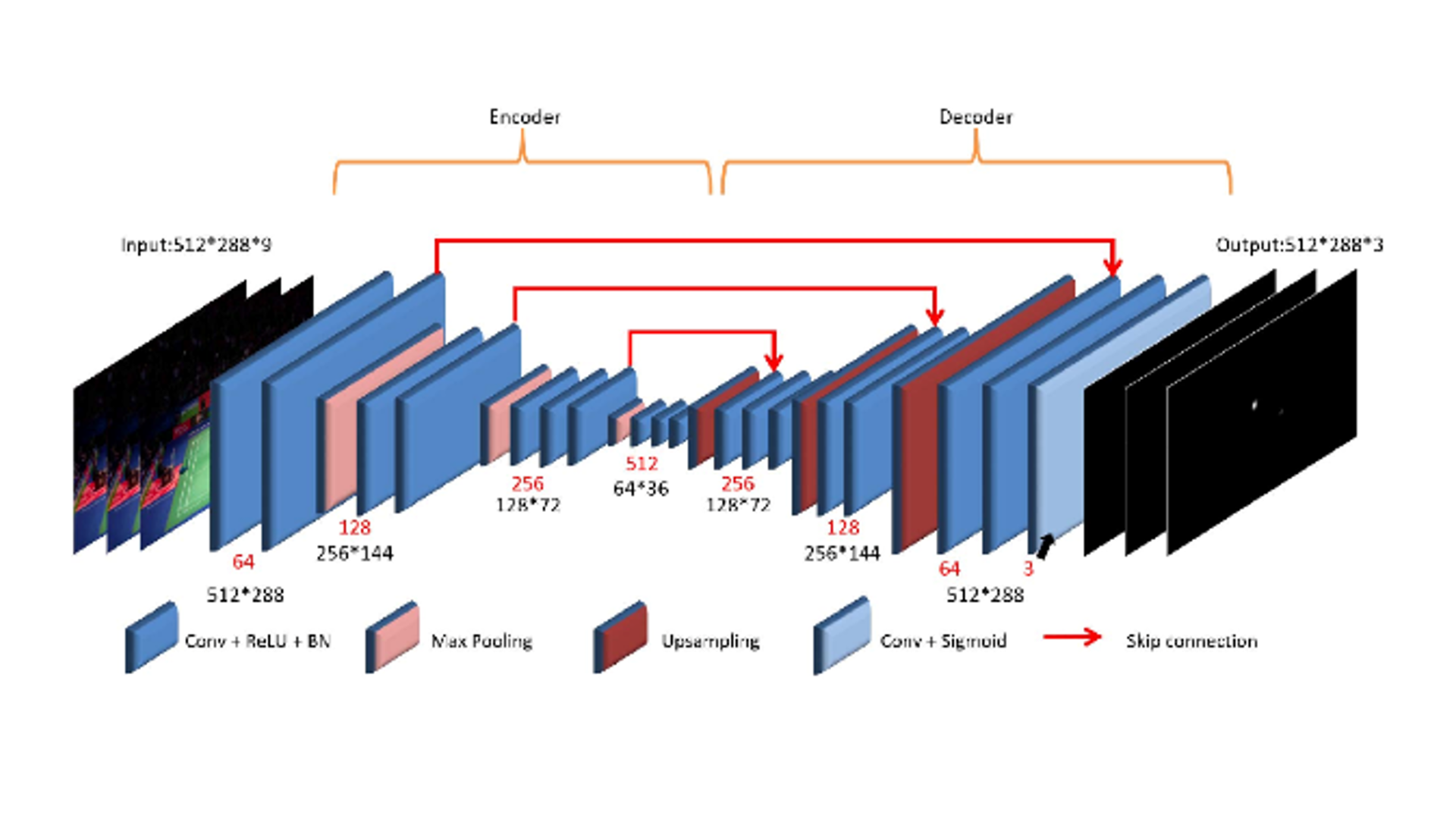
利用可選擇性殘差塊在改良式
階層編解碼器網路實現影像修復
在這篇論文當中,我們將基於
輕量型的階層式網路架構: U-Net 為基底,並改良自影像修復任務中效果很
好,但需消耗較大記憶體容量的殘差密集塊(RDB),成為一種效率更高、且
不會占據過多顯存的模塊稱為選擇性殘差塊(SRB)。 我們還改良了階層式網
路架構 U-Net,增加了門柱特徵路徑,稱為 M-Net+。 我們提出的 M-Net+相
較於傳統 U-Net,可以獲取更豐富的空間特徵資訊,並與 SRB 作結合達到相
輔相成的效果。 除此之外,我們還提出了基於影像修復中相當重要的兩個
評估指標: 峰值訊雜比(PSNR)與結構相似性(SSIM)的損失函數來優化我們
網路模型。 最終我們提出的網路架構適用於9種不同的影像修復任務>中的去噪、去模糊、
去雨、去霧與低光源的影像增強,並在定量指標與視覺質量上取得了非常不錯的成績。 此篇論文被選為 IEEE 2022 台北分會最佳碩博士論文獎🎉


半小波注意力在M-Net+上的應用於低光圖像增強
低光圖像增強是一個計算機視覺任務,旨在將暗圖像增強到適當的亮度。在圖像修復領域,這也被視為一個 ill-posed 問題。隨著深度神經網絡的成功,卷積神經網絡超越了傳統的基於算法的方法,並成為計算機視覺領域的主流。為了提高增強算法的性能,我們提出了一種基於改進的層次模型M-Net+的圖像增強網絡(HWMNet)。具體來說,我們在M-Net+上使用了半小波注意力塊,以豐富來自小波域的特徵。此外,在兩個圖像增強數據集上,我們的HWMNet在定量指標和視覺質量方面的表現都具有競爭力。

改進的層次結構 M-Net+ 用於盲圖像去噪
圖像去噪是一個長期存在的 ill-posed 問題。最近,卷積神經網絡 (CNNs) 逐漸成為焦點,幾乎主導了計算機視覺領域,並在不同層次的視覺任務中取得了令人印象深刻的成果。其中一個著名的層次結構 CNN 主幹是 U-Net,它在去噪和其他計算機視覺領域表現出色。然而,層次結構通常因重複取樣而導致空間信息的丟失,這對去噪性能,尤其是像去噪這樣的逐點操作任務產生了嚴重影響。本文提出了一種改進的層次主幹模型 M-Net+ 用於圖像去噪,以改善空間細節的丟失。此外,我們在兩個合成的高斯噪聲數據集上進行了測試,展示了我們模型的競爭性結果。
選擇性殘差 M-Net 用於真實圖像去噪
圖像修復是一項低層次的視覺任務,旨在將退化的圖像恢復為無噪聲的圖像。隨著深度神經網絡的成功,卷積神經網絡已超越傳統的修復方法,並成為計算機視覺領域的主流。為了提高去噪算法的性能,我們提出了一種基於層次結構的盲真實圖像去噪網絡(SRMNet),該結構從 U-Net 改進而來。具體而言,我們在層次結構 M-Net 上使用了一個具有殘差塊的選擇性內核,以豐富多尺度語義信息。此外,在兩個合成和兩個真實世界的噪聲數據集上,我們的 SRMNet 在定量指標和視覺質量方面均表現出競爭力。源代碼和預訓練模型可在以下鏈接獲取:https://github.com/FanChiMao/SRMNet。

SUNet: 基於 Swin Transformer 的 UNet 用於圖像去噪
圖像修復是一個具有挑戰性的 ill-posed 問題,並且長期以來一直是研究的難題。過去幾年,卷積神經網絡 (CNNs) 幾乎主導了計算機視覺領域,並在包括圖像修復在內的不同層次的視覺任務中取得了相當的成功。然而,最近基於 Swin Transformer 的模型也展示了令人印象深刻的表現,甚至超越了基於 CNN 的方法,成為高層次視覺任務的最新技術。在本文中,我們提出了一個名為 SUNet 的修復模型,該模型使用 Swin Transformer 層作為基本模塊,並將其應用於 UNet 架構來進行圖像去噪。

WBTP-VTON:基於全身和紋理保護的虛擬試穿網絡
基於圖像的虛擬服裝試穿系統越來越受歡迎。然而,許多挑戰仍有待解決。為此,我們提出了一種新的完全可學習的方法,稱為基於全身和紋理保護的虛擬試穿網絡 (WBTP-VTON),以應對該領域中的所有實際挑戰。首先,WBTP-VTON 模板轉換使用幾何匹配模塊 (GMM) 方法根據目標人物的體型來轉換目標衣服和褲子(或裙子)。第二部分是合成最終圖像,使生成的結果更逼真。最後,我們使用試穿模塊和合成遮罩將變形的衣服與最終圖像結合起來,以確保圖像的平滑度。經過在大型數據集上的實驗證明,我們的 WBTP-VTON 方法具有先進的虛擬試穿性能。